In my last diary I announced that the Diary flow rate meter is public and explained what the tool measured and why. I said that I'd let it run for awhile to gather data before making any conclusions. Over fifty megs of data later, I've got some pretty graphs illustrating the rate at which diaries are published on DailyKos, the changes since DK4 was introduced, and answers to some of your most pressing meta questions.
The Diary Flow Gauge
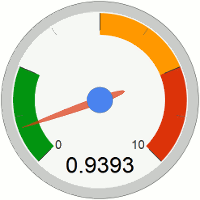
(DL/RR): the ratio of diaries published to those on the Recently Recommended List. Basically, all of them. :P
First, raw data of RR50, RR100 and DL100, by hour, is available in a CSV here. A GoogleDocs spreadsheet containing the data is here. You can import it into your own spreadsheet by putting the following text in cell A1:=importrange("tyskSd_JLNc1smoit4_8wNw", "DATA!A1:D1000")That's basically what I've done here, which is where all the pretty pictures are generated. Pretty pictures which answer questions like How long has the last diary been on the ___ list......in the last day?
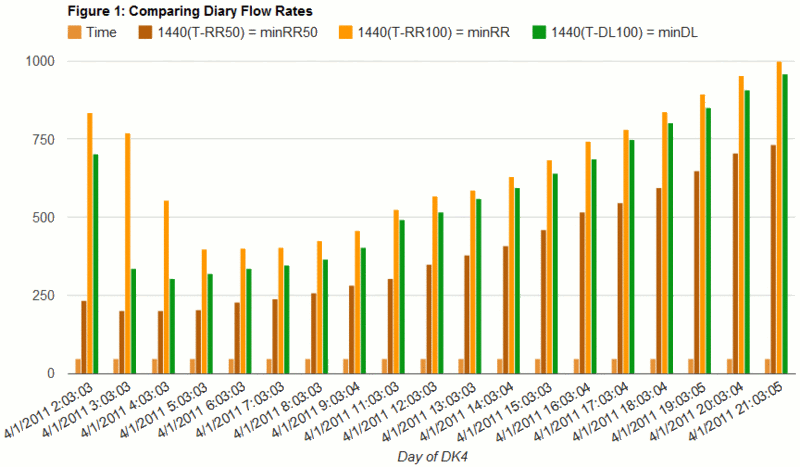
...in the last week?
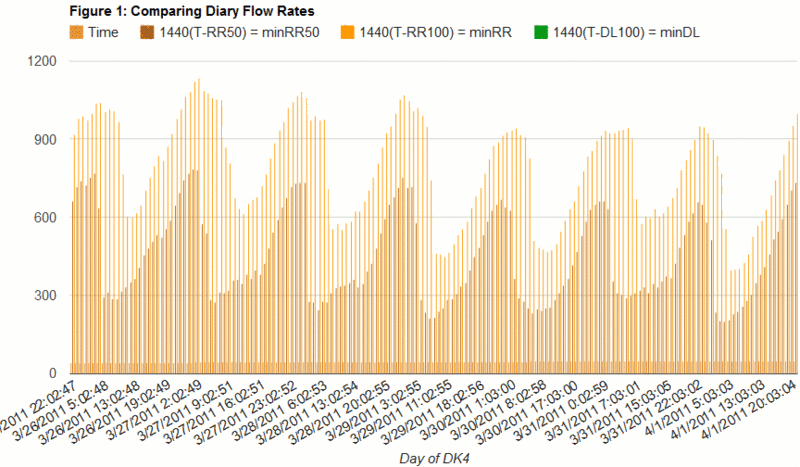 ...since opendna started collecting data?
...since opendna started collecting data?
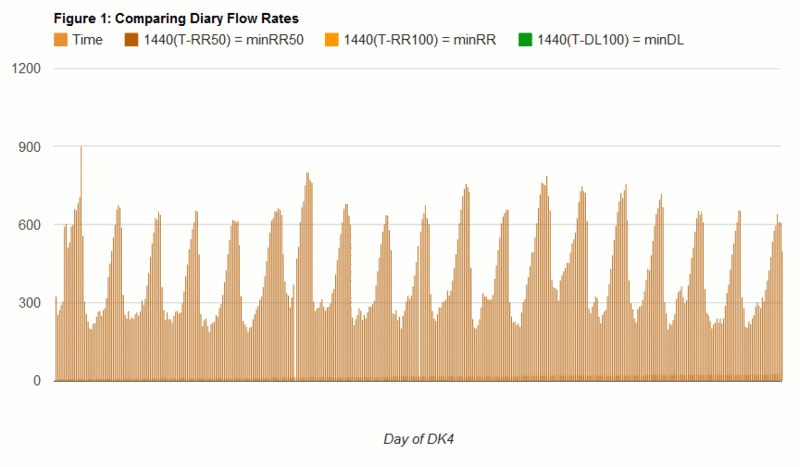
This and this let you look a little closer at the data.
Those who's been following along at home will realize that this last graph answers the question that Seneca Doane first posed set out to explore with the Diary Flow Gauge, 2/16-17/11: no, there is not an appreciable increase in the rate of turn-over of either the Recently Recommended (RR) or recent Diaries List (DL). In fact, both lists are so large relative to the rate of diaries published, that even after both the east and west coasts have gone published their evening diaries and gone to bed, the the older items on the Recently Recommended list have been there for around three hours (and if timed just right, might languish for over ten hours!).
Those observations early on caused me to question the value of our measurements. Perhaps we needed more precision and should select the DL 10 or RR10, which would tell you how long it took for the last 10 diaries to be published or hit the Recently Recommended list. I left the sampling alone because it is meaningful (is it on the first page?), might have changed (if the Firehose Hypothesis were correct) and, frankly, I couldn't come up with a good research question to justify messing it. Anyway, the data's there for you to use. Maybe you'll find something interesting in there that I didn't, or even a new question that should be asked. If so, drop me a line @gmail and we'll start filtering the datasets.
Getting on with it...
Updated by opendna at Fri Apr 08, 2011 at 04:24 PM EDT
aoeu pointed out that the images generated by GoogleDocs were breaking so I replaced them with ones hosted at Photobucket. (Damn you, Google!)
